ESOL regression#
In this tutorial we provide a simple example of training a random forest model on the ESOL dataset,
a dataset of molecules and their aqueous solubility. We require the rdkit package, so make sure to pip install 'molflux[rdkit]' to follow along!
Loading the ESOL dataset#
First, let’s load the ESOL dataset
from molflux.datasets import load_dataset
dataset = load_dataset("esol")
print(dataset)
dataset[0]
Repo card metadata block was not found. Setting CardData to empty.
Dataset({
features: ['smiles', 'log_solubility'],
num_rows: 1126
})
{'smiles': 'OCC3OC(OCC2OC(OC(C#N)c1ccccc1)C(O)C(O)C2O)C(O)C(O)C3O ',
'log_solubility': -0.77}
The loaded dataset is an instance of a HuggingFace Dataset (for more info, see the docs).
You can see that there are two columns: smiles and log_solubility.
Featurising#
Now, we will featurise the dataset. For this, we will use the Morgan and MACCS fingerprints from rdkit and the
featurise_dataset function from molflux.datasets.
from molflux.datasets import featurise_dataset
from molflux.features import load_from_dicts as load_representations_from_dicts
featuriser = load_representations_from_dicts(
[
{"name": "morgan"},
{"name": "maccs_rdkit"},
]
)
featurised_dataset = featurise_dataset(dataset, column="smiles", representations=featuriser)
print(featurised_dataset)
Dataset({
features: ['smiles', 'log_solubility', 'smiles::morgan', 'smiles::maccs_rdkit'],
num_rows: 1126
})
You can see that we now have two extra columns for each fingerprint we used.
Splitting#
Next, we need to split the dataset. For this, we use the simple shuffle_split (random split) with 80% training and
20% test. To split the dataset, we use the split_dataset function from molflux.datasets.
from molflux.datasets import split_dataset
from molflux.splits import load_from_dict as load_split_from_dict
shuffle_strategy = load_split_from_dict(
{
"name": "shuffle_split",
"presets": {
"train_fraction": 0.8,
"validation_fraction": 0.0,
"test_fraction": 0.2,
}
}
)
split_featurised_dataset = next(split_dataset(featurised_dataset, shuffle_strategy))
print(split_featurised_dataset)
DatasetDict({
train: Dataset({
features: ['smiles', 'log_solubility', 'smiles::morgan', 'smiles::maccs_rdkit'],
num_rows: 900
})
validation: Dataset({
features: ['smiles', 'log_solubility', 'smiles::morgan', 'smiles::maccs_rdkit'],
num_rows: 0
})
test: Dataset({
features: ['smiles', 'log_solubility', 'smiles::morgan', 'smiles::maccs_rdkit'],
num_rows: 226
})
})
Training the model#
We can now turn to training the model! We choose the random_forest_regressor (which we access from the sklearn package).
To do so, we need to define the model config and the x_features and the y_features.
Once trained, we will get some predictions and compute some metrics!
import json
from molflux.modelzoo import load_from_dict as load_model_from_dict
from molflux.metrics import load_suite
import matplotlib.pyplot as plt
model = load_model_from_dict(
{
"name": "random_forest_regressor",
"config": {
"x_features": ['smiles::morgan', 'smiles::maccs_rdkit'],
"y_features": ['log_solubility'],
}
}
)
model.train(split_featurised_dataset["train"])
preds = model.predict(split_featurised_dataset["test"])
regression_suite = load_suite("regression")
scores = regression_suite.compute(
references=split_featurised_dataset["test"]["log_solubility"],
predictions=preds["random_forest_regressor::log_solubility"],
)
print(json.dumps({k: round(v, 2) for k, v in scores.items()}, indent=4))
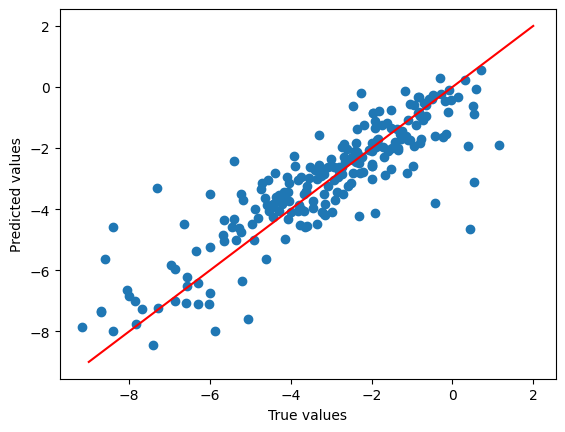
plt.scatter(
split_featurised_dataset["test"]["log_solubility"],
preds["random_forest_regressor::log_solubility"],
)
plt.plot([-9, 2], [-9, 2], c='r')
plt.xlabel("True values")
plt.ylabel("Predicted values")
plt.show()
{
"explained_variance": 0.78,
"max_error": 4.46,
"mean_absolute_error": 0.69,
"mean_squared_error": 1.02,
"root_mean_squared_error": 1.01,
"median_absolute_error": 0.45,
"r2": 0.78,
"spearman::correlation": 0.89,
"spearman::p_value": 0.0,
"pearson::correlation": 0.88,
"pearson::p_value": 0.0
}
ESOL training using a yaml file#
All configs for above pipeline can also be put in a single yaml file:
---
version: v1
kind: datasets
specs:
- name: esol
config: { }
---
version: v1
kind: representations
specs:
- name: morgan
config: { }
- name: maccs_rdkit
config: { }
---
version: v1
kind: splits
specs:
- name: shuffle_split
presets:
train_fraction: 0.8
validation_fraction: 0.0
test_fraction: 0.2
---
version: v1
kind: models
specs:
- name: random_forest_regressor
config:
x_features: [ 'smiles::morgan', 'smiles::maccs_rdkit' ]
y_features: [ 'log_solubility' ]
---
version: v1
kind: metrics
specs:
- name: regression
config: { }
We can now run the same pipeline with the settings in the yaml file using the load_from_yaml logic for all submodules:
import json
import matplotlib.pyplot as plt
from molflux.datasets import load_from_yaml as load_dataset_from_yaml
from molflux.features import load_from_yaml as load_representations_from_yaml
from molflux.datasets import featurise_dataset
from molflux.splits import load_from_yaml as load_split_from_yaml
from molflux.datasets import split_dataset
from molflux.modelzoo import load_from_yaml as load_model_from_yaml
from molflux.metrics import load_suite
yaml_file_path = "esol_reg.yaml"
# Load the dataset
dataset = load_dataset_from_yaml(yaml_file_path) # A dictionary with a single dataset is returned
dataset = dataset["dataset-0"]
# Load the representations
featuriser = load_representations_from_yaml(yaml_file_path)
# Featurise the dataset
featurised_dataset = featurise_dataset(
dataset, column="smiles", representations=featuriser
)
# Load the split strategy
strategies = load_split_from_yaml(yaml_file_path) # A dictionary with a single strategy is returned
split_strategy = strategies["shuffle_split"]
# Split the dataset
split_featurised_dataset = next(split_dataset(featurised_dataset, split_strategy))
# Load the model
models = load_model_from_yaml(yaml_file_path)
model = models["random_forest_regressor"]
# Train the model
model.train(split_featurised_dataset["train"])
# Predict the test set
preds = model.predict(split_featurised_dataset["test"])
# Compute metrics
regression_suite = load_suite("regression")
scores = regression_suite.compute(
references=split_featurised_dataset["test"]["log_solubility"],
predictions=preds["random_forest_regressor::log_solubility"],
)
print(json.dumps({k: round(v, 2) for k, v in scores.items()}, indent=4))
# Plot true vs predicted values
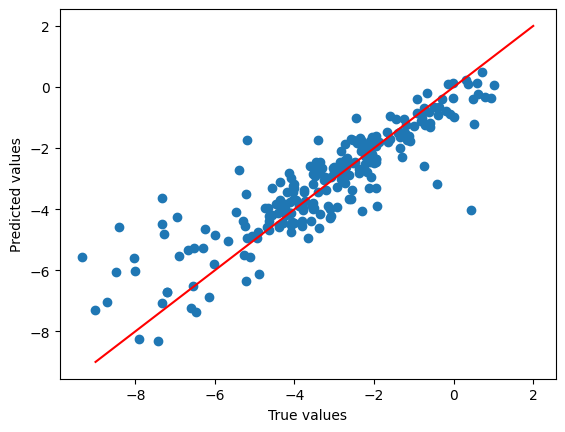
plt.scatter(
split_featurised_dataset["test"]["log_solubility"],
preds["random_forest_regressor::log_solubility"],
)
plt.plot([-9, 2], [-9, 2], c='r')
plt.xlabel("True values")
plt.ylabel("Predicted values")
plt.show()
Repo card metadata block was not found. Setting CardData to empty.
{
"explained_variance": 0.75,
"max_error": 5.09,
"mean_absolute_error": 0.77,
"mean_squared_error": 1.17,
"root_mean_squared_error": 1.08,
"median_absolute_error": 0.57,
"r2": 0.75,
"spearman::correlation": 0.87,
"spearman::p_value": 0.0,
"pearson::correlation": 0.87,
"pearson::p_value": 0.0
}