QM9 with uncertainty#
In this tutorial we provide an example of training a model with uncertainty on the QM9 dataset. To do this, we will use a
model that supports uncertainty prediction, ensemble_ani_model. For more information on which models support uncertainty,
check out the models page. We require the rdkit package, so make sure to pip install 'physicsml[rdkit]'
to follow along!
Loading the QM9 dataset#
First, let’s load a truncated QM9 dataset with 1000 datapoints. For more information on the loading
and using dataset, see the molflux documentation.
from molflux.datasets import load_dataset_from_store
dataset = load_dataset_from_store("gdb9_trunc.parquet")
print(dataset)
Dataset({
features: ['mol_bytes', 'mol_id', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u298', 'h298', 'g298', 'cv', 'u0_atom', 'u298_atom', 'h298_atom', 'g298_atom'],
num_rows: 1000
})
Note
The dataset above is a truncated version to run efficiently in the docs. For running this locally, load the entire dataset by doing
from molflux.datasets import load_dataset
dataset = load_dataset("gdb9", "rdkit")
You can see that there is the mol_bytes column (which is the rdkit serialisation of the 3d molecules and the
remaining columns of computes properties.
Featurising#
Next, we will featurise the dataset. The ANI model requires only the atomic numbers, coordinates, and atomic self energies.
For more information on the physicsml features, see here.
import logging
logging.disable(logging.CRITICAL)
from molflux.core import featurise_dataset
featurisation_metadata = {
"version": 1,
"config": [
{
"column": "mol_bytes",
"representations": [
{
"name": "physicsml_features",
"config": {
"atomic_number_mapping": {
1: 0,
6: 1,
7: 2,
8: 3,
9: 4,
},
"atomic_energies": {
1: -0.6019805629746086,
6: -38.07749583990695,
7: -54.75225433326539,
8: -75.22521603087064,
9: -99.85134426752529
},
"backend": "rdkit",
},
"as": "{feature_name}"
}
]
}
]
}
# featurise the mols
featurised_dataset = featurise_dataset(
dataset,
featurisation_metadata=featurisation_metadata,
num_proc=4,
batch_size=100,
)
print(featurised_dataset)
Dataset({
features: ['mol_bytes', 'mol_id', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u298', 'h298', 'g298', 'cv', 'u0_atom', 'u298_atom', 'h298_atom', 'g298_atom', 'physicsml_atom_idxs', 'physicsml_atom_numbers', 'physicsml_coordinates', 'physicsml_total_atomic_energy'],
num_rows: 1000
})
You can see that we now have the extra columns for
physicsml_atom_idxs: The index of the atoms in the moleculesphysicsml_atom_numbers: The atomic numbers mapped using the mapping dictionaryphysicsml_coordinates: The coordinates of the atomsphysicsml_total_atomic_energy: The total atomic self energy
Splitting#
Next, we need to split the dataset. For this, we use the simple shuffle_split (random split) with 80% training and
20% test. To split the dataset, we use the split_dataset function from molflux.datasets.
from molflux.datasets import split_dataset
from molflux.splits import load_from_dict as load_split_from_dict
shuffle_strategy = load_split_from_dict(
{
"name": "shuffle_split",
"presets": {
"train_fraction": 0.8,
"validation_fraction": 0.0,
"test_fraction": 0.2,
}
}
)
split_featurised_dataset = next(split_dataset(featurised_dataset, shuffle_strategy))
print(split_featurised_dataset)
DatasetDict({
train: Dataset({
features: ['mol_bytes', 'mol_id', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u298', 'h298', 'g298', 'cv', 'u0_atom', 'u298_atom', 'h298_atom', 'g298_atom', 'physicsml_atom_idxs', 'physicsml_atom_numbers', 'physicsml_coordinates', 'physicsml_total_atomic_energy'],
num_rows: 800
})
validation: Dataset({
features: ['mol_bytes', 'mol_id', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u298', 'h298', 'g298', 'cv', 'u0_atom', 'u298_atom', 'h298_atom', 'g298_atom', 'physicsml_atom_idxs', 'physicsml_atom_numbers', 'physicsml_coordinates', 'physicsml_total_atomic_energy'],
num_rows: 0
})
test: Dataset({
features: ['mol_bytes', 'mol_id', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u298', 'h298', 'g298', 'cv', 'u0_atom', 'u298_atom', 'h298_atom', 'g298_atom', 'physicsml_atom_idxs', 'physicsml_atom_numbers', 'physicsml_coordinates', 'physicsml_total_atomic_energy'],
num_rows: 200
})
})
For more information about splitting datasets, see the molflux splitting documentation.
Training the model#
We can now turn to training the model! The ensemble_ani_model is composed of a single AEV computer and a number of
neural network heads. These heads are trained from different randomly initialised parameters with the idea that each one
converges to a different minimum of the loss landscape. The final prediction is the mean of the individual predictions
with a standard deviation computed from their variance. The idea is that if all the models produce a similar prediction for
a datapoint then it must be “more certain”, whereas if the predictions are different then the uncertainty is higher.
We start by specifying the model config and the x_features, the y_features, and the n_models the number of
heads to use.
from molflux.modelzoo import load_from_dict as load_model_from_dict
model = load_model_from_dict(
{
"name": "ensemble_ani_model",
"config": {
"x_features": [
'physicsml_atom_idxs',
'physicsml_atom_numbers',
'physicsml_coordinates',
'physicsml_total_atomic_energy',
],
"y_features": ['u0'],
"which_ani": "ani2",
"n_models": 3,
"y_graph_scalars_loss_config": {
"name": "MSELoss",
},
"optimizer": {
"name": "AdamW",
"config": {
"lr": 1e-3,
}
},
"datamodule": {
"y_graph_scalars": ['u0'],
"pre_batch": "in_memory",
"train": {"batch_size": 256},
"validation": {"batch_size": 128},
},
"trainer": {
"max_epochs": 20,
"accelerator": "cpu",
"logger": False,
}
}
}
)
model.train(
train_data=split_featurised_dataset["train"]
)
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/torch/jit/_trace.py:763: TracerWarning: Encountering a list at the output of the tracer might cause the trace to be incorrect, this is only valid if the container structure does not change based on the module's inputs. Consider using a constant container instead (e.g. for `list`, use a `tuple` instead. for `dict`, use a `NamedTuple` instead). If you absolutely need this and know the side effects, pass strict=False to trace() to allow this behavior.
traced = torch._C._create_function_from_trace(
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/torchani/aev.py:16: UserWarning: cuaev not installed
warnings.warn("cuaev not installed")
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/physicsml/lightning/pre_batching_in_memory.py:53: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:424: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/utilities/data.py:105: Total length of `dict` across ranks is zero. Please make sure this was your intention.
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/torch/storage.py:414: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
return torch.load(io.BytesIO(b))
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/core/module.py:516: You called `self.log('train/total/y_graph_scalars/model_0', ..., logger=True)` but have no logger configured. You can enable one by doing `Trainer(logger=ALogger(...))`
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/core/module.py:516: You called `self.log('train/total/y_graph_scalars/model_1', ..., logger=True)` but have no logger configured. You can enable one by doing `Trainer(logger=ALogger(...))`
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/core/module.py:516: You called `self.log('train/total/y_graph_scalars/model_2', ..., logger=True)` but have no logger configured. You can enable one by doing `Trainer(logger=ALogger(...))`
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/core/module.py:516: You called `self.log('train/total/y_graph_scalars', ..., logger=True)` but have no logger configured. You can enable one by doing `Trainer(logger=ALogger(...))`
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/core/module.py:516: You called `self.log('train/total/loss', ..., logger=True)` but have no logger configured. You can enable one by doing `Trainer(logger=ALogger(...))`
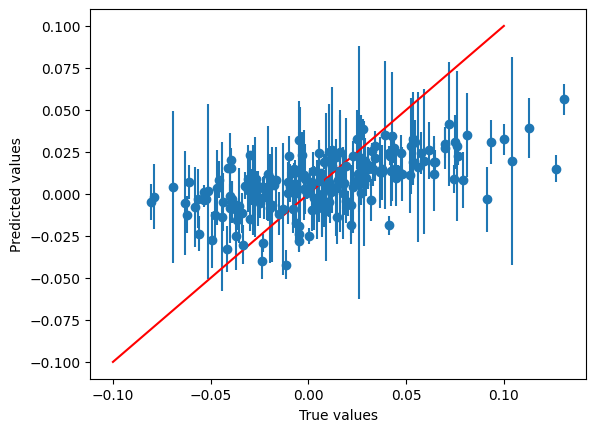
Now that the model is trained, we can inference it to get some predictions! Apart from the usual predict method (which
returns the energy predictions), the uncertainty models support predict_with_std which returns a tuple of energy
predictions and their corresponding standard deviation predictions. For more information about the uncertainty API in
physicsml models, see the molflux documentation on which it is based.
Below we demonstrate how to get predictions and standard deviations and plot them!
import json
import matplotlib.pyplot as plt
from molflux.metrics import load_suite
preds, stds = model.predict_with_std(
split_featurised_dataset["test"],
datamodule_config={"predict": {"batch_size": 256}}
)
regression_suite = load_suite("regression")
scores = regression_suite.compute(
references=split_featurised_dataset["test"]["u0"],
predictions=preds["ensemble_ani_model::u0"],
)
print(json.dumps(scores, indent=4))
true_shifted = [x - e for x, e in zip(split_featurised_dataset["test"]["u0"], split_featurised_dataset["test"]["physicsml_total_atomic_energy"])]
pred_shifted = [x - e for x, e in zip(preds["ensemble_ani_model::u0"], split_featurised_dataset["test"]["physicsml_total_atomic_energy"])]
plt.errorbar(
true_shifted,
pred_shifted,
yerr=stds["ensemble_ani_model::u0::std"],
fmt='o',
)
plt.plot([-0.1, 0.1], [-0.1, 0.1], c='r')
plt.xlabel("True values")
plt.ylabel("Predicted values")
plt.show()
/home/runner/work/physicsml/physicsml/.cache/nox/docs_build-3-11/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:424: The 'predict_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
{
"explained_variance": 0.9999994394653372,
"max_error": 0.1116943359375,
"mean_absolute_error": 0.026659088134765627,
"mean_squared_error": 0.0011080007860437035,
"root_mean_squared_error": 0.0332866457613816,
"median_absolute_error": 0.0223541259765625,
"r2": 0.9999994394623094,
"spearman::correlation": 0.9998574964374111,
"spearman::p_value": 0.0,
"pearson::correlation": 0.9999997204336573,
"pearson::p_value": 0.0
}